Rebuilding the Career Ladder in the Machine Age – An AI Soft Landing Scenario
LAST UPDATED: June 20, 2026 at 11:02 AM

by Braden Kelley and Art Inteligencia
The Silent Erasure of the Learning Runway
For generations, professional growth followed a predictable, slow-rolling rhythm: enter at the bottom, grind through repetitive entry-level tasks, absorb tacit knowledge from senior colleagues by osmosis, and gradually earn the right to make strategic decisions. It was an expensive, deeply human, and highly localized model. Entry-level jobs were never just about immediate output; they were society’s primary apprenticeship infrastructure. They provided the safe sandboxes where junior talent could observe experts, make low-risk mistakes, and build foundational professional confidence.
Today, generative AI and autonomous agents threaten to obliterate that foundation by instantly executing the very baseline tasks—writing basic code, drafting initial copy, analyzing standardized datasets—that used to be the domain of the junior professional. Much of the current AI conversation focuses on this displacement, viewing it as a straightforward labor crisis. However, looking at this shift simply as a “job destruction” event misses the true structural vulnerability: we aren’t just losing entry-level jobs; we are losing our capability-building infrastructure. If machines do all the beginner work, how do humans ever gain the context, failure-resilience, and judgment required to become experts?
The answer is not to fight automation, but to completely rethink organizational design. The future of work is not an empty ladder, but an AI Apprenticeship Economy where intelligent systems shift from being automated replacements to scalable, human-centered capability accelerators. Instead of erasing the path to expertise, the next generation of organizations must use artificial intelligence as the greatest learning engine humanity has ever created—shifting the ultimate competitive advantage from talent acquisition to talent manufacturing.
I. The Entry-Level Job Crisis May Actually Be a Learning Model Crisis
The current public discourse surrounding artificial intelligence in the workplace is dominated by a single, pervasive anxiety: mass displacement at the bottom of the pyramid. Executives look at the capabilities of modern language models and autonomous agents and see an immediate opportunity to optimize bottom-line efficiency. The calculations seem straightforward. Why hire a team of junior analysts, junior developers, or entry-level copywriters when an AI assistant can generate reports, debug code, and churn out marketing assets in a fraction of the time and at a fraction of the cost?
This focus on immediate productivity gains exposes a dangerous leadership blindspot. Entry-level positions have never been purely about transactional output. Their true, hidden function has always been cultural and developmental—they serve as society’s primary capability-building infrastructure. By automating away the “grunt work,” organizations are inadvertently dismantling the very runways that allowed young professionals to transition from theoretical knowledge to practical wisdom.
To understand what is at stake, we must map the critical components of the traditional entry-level learning model that pure automation threatens to erase:
- The Observation of Mastery: Junior professionals learn how to navigate organizational politics, manage client relationships, and handle ambiguity not from textbooks, but by sitting in rooms and watching senior leaders behave.
- The Safe Sandbox: Low-stakes, repetitive tasks provide a safe environment to make mistakes, receive feedback, and build resilience without risking mission-critical organizational assets.
- The Development of Taste and Judgment: Reviewing data, drafting initial briefs, and filtering information forces a novice to actively practice discrimination—discovering the subtle difference between an output that is technically correct and one that is strategically brilliant.
- Contextual Assimilation: Spending time in the operational weeds allows an individual to internalize the unique language, unwritten rules, and historical context of a specific enterprise.
When an organization replaces its junior cohort with automated systems, it gains an immediate spike in efficiency but incurs a massive, hidden deficit in long-term capability. We are creating an unsustainable corporate ecosystem: a top-heavy structure populated by aging experts with no incoming pipeline of seasoned talent to eventually replace them.
The fundamental challenge of the machine age is not that we will run out of tasks for humans to do. The challenge is that if we allow machines to perform all the beginner tasks, we eliminate the very experiences humans need to become intelligent. The crisis we face is not an employment crisis; it is a systemic learning crisis that requires an entirely new framework for professional growth.
II. The Rise of the AI Apprenticeship Economy
The structural vulnerability of the learning crisis forces a radical pivot in how we view technology. The AI Apprenticeship Economy emerges the moment progressive organizations stop treating artificial intelligence as a tool for labor subtraction and begin deploying it as an infrastructure for human amplification. In this new paradigm, AI is repositioned from an automated replacement for junior talent into the ultimate accelerator for human capability development.
Instead of using machines to bypass the novice altogether, we must wrap machines around the novice to collapse the distance between inexperience and mastery. AI becomes the hyper-personalized tutor, the infinite simulator, the objective coach, and the safe practice environment. The technology allows an apprentice to compress decades of tacit experience into months of hyper-focused, simulated engagement.
To understand how this fundamentally alters the professional life cycle, we must look at how the legacy career trajectory compares directly to the accelerated, AI-augmented model:
| Dimension | The Traditional Career Model | The AI-Enabled Apprenticeship Model |
|---|---|---|
| Core Sequence | Education → Entry Job → Osmosis → Gradual Expertise | Education → AI Simulation → Real Application → Accelerated Expertise |
| Feedback Loop | Delayed, intermittent, dependent on manager availability. | Instantaneous, constant, data-driven, and emotionally safe. |
| Exposure Rate | Dependent on the random luck of which projects land on a desk. | Systematic exposure to thousands of curated operational scenarios. |
| Role of Novice | Transactional order-taker focused on raw data/text execution. | AI conductor-in-training focused on validation and context framing. |
Under the traditional model, developing true business acumen required a massive runway of time because humans had to wait for real-world scenarios to organically occur. A junior professional might only witness a major corporate turnaround, a severe product failure, or a complex negotiation a handful of times in their first five years.
The AI Apprenticeship Economy removes this constraint. By leveraging specialized internal models, a junior employee can interact with synthetic customer segments, stress-test strategic frameworks against historical data, and defend their ideas against an AI trained to mimic the company’s toughest board members. The apprentice gains profound exposure before they are granted high-stakes authority, arriving at real-world projects with an already sharpened sense of judgment.
III. AI as the World’s First Scalable Mentor
Throughout history, the greatest bottleneck to human development has been the scarcity of elite mentorship. True apprenticeship has always been a luxury good, fundamentally constrained by physics, geometry, and economics. A master craftsman, a visionary designer, or a brilliant corporate strategist only has so many hours in a day, so much patience, and the capacity to deeply guide a small handful of protégés. Because of this structural limitation, world-class professional incubation remained an accidental privilege—dependent on landing the right role, in the right office, under the right manager.
Artificial intelligence breaks this scarcity model forever. In the AI Apprenticeship Economy, we transition from an era of rationed guidance to an era of ubiquitous, zero-marginal-cost mentorship. By training specialized AI agents on the accumulated institutional knowledge, decision-making frameworks, and historical case studies of an enterprise, organizations can provide every single employee with an always-on, hyper-personalized cognitive mentor. This agent does not do the work for the apprentice; instead, it acts as a Socratic sparring partner that forces the apprentice to think deeper, challenge assumptions, and safely build creative muscle.
To see this shift in action, we can look at how the role of scalable mentorship translates across distinct corporate functions:
- The Junior Product Manager: Instead of executing basic backlog grooming, the novice PM utilizes an AI simulation framework to stress-test an upcoming feature rollout. The AI simulates high-pressure executive board reviews, challenges the PM’s monetization assumptions, generates synthetic customer friction points based on historical user research, and provides an objective critique of their strategic messaging before they ever present to human leadership.
- The New Experience Designer: Rather than spending days manually moving pixels for a single layout variation, the apprentice designer directs an AI system to generate hundreds of radical user-flow permutations overnight. The AI then acts as a design critic, evaluating each option against established behavioral science principles, pointing out accessibility vulnerabilities, and challenging the designer to justify their aesthetic and functional choices.
- The Associate Systems Engineer: Instead of watching an expert fix infrastructure bugs from a distance, the new engineer works inside an isolated, simulated environment. The AI mentor deliberately injects complex, real-world architectural failures into the system, dynamically coaching the engineer through conversational troubleshooting, explaining hidden dependencies, and ensuring they understand the underlying system mechanics before touching live code.
This evolution fundamentally alters the relationship between the novice and the organization. By deploying AI as a cognitive coach, we remove the fear of failure that typically paralyzes junior talent. The apprentice can ask seemingly simple questions without judgment, test highly unconventional ideas in a safe sandbox, and master foundational patterns at their own individual pace. The result is a workforce that gains a profound depth of operational exposure and context before they are ever handed the keys to high-stakes organizational authority.
IV. The Compression of Expertise & The New Human Core
Every major technological paradigm shift can be fundamentally measured by how drastically it compresses human capability and alters the velocity of knowledge transfer. The invention of the printing press decentralized knowledge storage, instantly removing the requirement for memorization and manual transcription. The expansion of the internet decentralized information retrieval, turning the challenge of finding data into a simple search query.
Artificial intelligence represents a far more profound compression: it is the decentralization and acceleration of cognitive synthesis and application. Because machines can now handle the heavy lifting of raw execution, the historical timeline required to build business acumen is collapsing. The legacy operational question—“How many years of repetitive taskwork does it take to make someone competent?”—is rendered obsolete. The modern, strategic question becomes: “How quickly can an individual build exceptional judgment when wrapped in the right high-frequency feedback systems?”
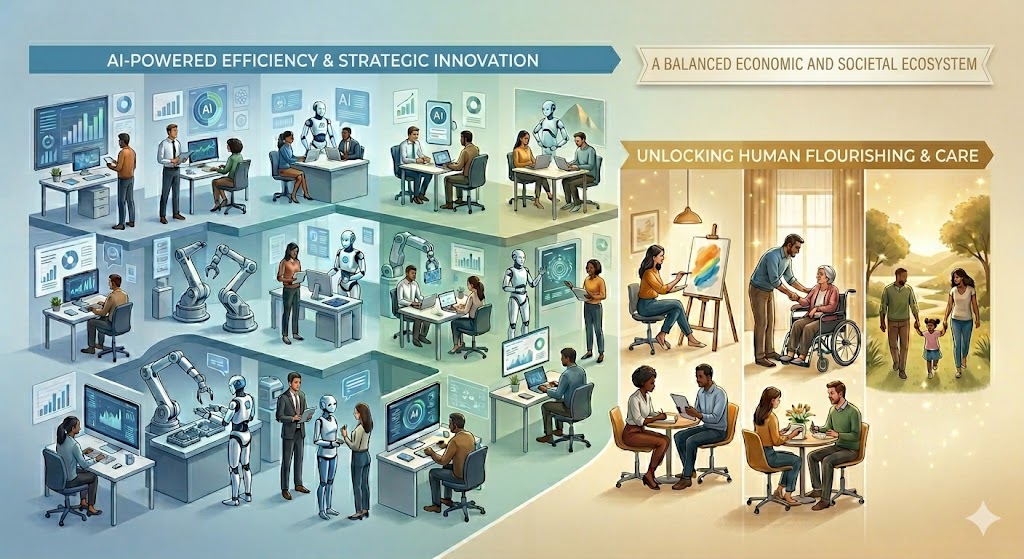
This compression does not render human capability irrelevant; rather, it drastically elevates and clarifies what the unique human value-add actually is. When information is cheap and generation is instant, raw knowledge becomes a commodity. The true premium shifts to the qualities that machines cannot synthesize. In the AI Apprenticeship Economy, the future expert is not the person who possesses all the answers, but the person who masters the following human core capabilities:
- Systemic Taste and Intentionality: The capability to look at an infinite sea of AI-generated permutations and intuitively discern which option possesses genuine strategic depth, aesthetic brilliance, and structural harmony.
- Ethical and Contextual Discernment: The capacity to look beyond immediate efficiency metrics and accurately evaluate the second- and third-order human consequences of an organizational decision.
- Socratic Framing and Inquiry: The art of knowing how to interrogate an ecosystem, challenge machine biases, and formulate the exact, nuanced questions that unlock breakthrough innovations.
- Relational and Empathetic Influence: The distinctly human ability to navigate cross-functional ambiguity, manage emotional friction, build psychological safety, and align diverse human stakeholders around a shared vision.
We must stop measuring a professional’s value by the volume of artifacts they manually produce. The AI apprentice is insulated from the exhausting, low-leverage grind of pure text or code creation, allowing them to focus their cognitive energy on validation, orchestration, and alignment from day one. By shifting the focus of development from execution to judgment, we don’t just speed up the career path—we fundamentally elevate the quality of the experts we are manufacturing.
V. Moving from Talent Acquisition to Talent Manufacturing
For decades, corporate leadership has operated under a flawed talent strategy: treating human capability as an external commodity to be extracted, poached, or bought on the open market. When an organization faced a capability deficit, the standard playbook was simply to launch a costly recruitment campaign to secure pre-packaged, mid-career experts. This reactive model is completely unviable in an era where rapid technological disruption changes required skill sets faster than traditional educational or hiring pipelines can adapt.
The AI Apprenticeship Economy demands a fundamental shift in executive mindset. Forward-thinking companies must transition from a philosophy of talent acquisition to a disciplined strategy of talent manufacturing. Organizations can no longer view themselves as mere consumers of human skill; they must redesign themselves as sophisticated capability factories, learning ecosystems, and high-velocity acceleration environments.
To successfully manufacture capability at scale, organizations must establish a new operational infrastructure that prioritizes the human experience of growth over legacy output metrics. This requires the deployment of two core architectural concepts:
- The Experience Management Office (XMO): Just as traditional project management offices (PMOs) govern timelines and deliverables, the XMO is tasked with governing the quality, velocity, and design of human experience within the enterprise. The XMO treats the internal learning journey of an employee as a mission-critical product, ensuring that automation loops are deliberately paired with human development milestones.
- Experience Level Measures (XLMs): Legacy metrics focus entirely on lagging performance indicators—KPIs, quarterly outputs, or hours billed. XLMs, by contrast, are leading metrics that actively track an individual’s growth velocity. They measure how quickly an apprentice is exposed to new operational contexts, the depth of their problem-framing capability, how effectively they navigate simulated failure states, and the speed at which their decision-making aligns with the organization’s top experts.
The ultimate competitive advantage of the next decade will not belong to the enterprise with the largest capital reserves, the most proprietary data, or the most advanced raw computing power. Technology is an easily replicated commodity. The companies that dominate will be those that intentionally build the fastest, most predictable pipeline for transforming a motivated novice into a highly contributing, strategic expert. By treating talent development as a core manufacturing process, these organizations create an insurmountable moat of institutional agility and human resilience.
VI. The Anatomy of the AI-Augmented Apprentice Role
As organizations successfully transition into capability factories, a completely new job category inevitably replaces the traditional entry-level role: the AI-Augmented Apprentice. Rather than using automation to squeeze human labor out of the bottom of the corporate pyramid, forward-thinking enterprises are systematically redesigning junior positions. The goal of this new role is no longer to pay someone a baseline wage to execute low-risk, repetitive tasks until they happen to absorb experience over time; the goal is to position them as an orchestrator from day one.
The AI-Augmented Apprentice does not spend their first year format-checking slide decks, manually copy-editing documents, or writing boilerplate code. Instead, they act as an AI Conductor-in-Training. They are given immediate, high-leverage toolsets that handle the heavy lifting of execution, allowing them to focus their cognitive energy entirely on problem-framing, prompt orchestration, cross-functional synthesis, and rigorous verification.
This shift dramatically alters the value contribution timeline of junior talent. By pairing an apprentice with a hyper-specialized AI system, the organization creates a powerful symbiotic relationship characterized by unique operational dynamics:
- Immediate Strategic Leverage: Because the apprentice can generate high-fidelity prototypes, deep market syntheses, or functional code blocks within minutes via AI, they can participate in high-level strategic ideation months—if not years—ahead of legacy corporate schedules.
- Continuous Human-in-the-Loop Validation: The apprentice’s primary responsibility shifts from creation to critique. They are trained to scrutinize machine outputs, check for hallucinations, challenge algorithmic biases, and inject the critical organizational context that the model lacks.
- Active Framework Application: Armed with generative tools, the apprentice can instantly apply complex organizational frameworks—such as human-centered design principles or deep strategic foresight models—directly to live data, testing variations at an unprecedented scale.
This evolution represents the ultimate win-win for the enterprise and the individual. The organization unlocks an incredibly agile, high-output contributor who injects fresh perspective into complex ecosystems almost immediately. Meanwhile, the professional avoids the soul-crushing burnout of low-leverage corporate grind, stepping directly into an environment designed to accelerate their cognitive growth, sharpen their business taste, and respect their human potential.
VII. Navigating the Dark Side of Compressed Learning
While the potential of the AI Apprenticeship Economy is immense, implementing it is not without profound systemic hazards. Collapsing the distance between novice and expert requires more than just deploying sophisticated software; it demands a hyper-vigilant approach to the unintended consequences of rapid cognitive acceleration. If leaders blindly optimize for speed without safeguarding the human elements of growth, they risk building an fragile workforce that possesses technical capability but lacks deep foundational wisdom.
To build a resilient learning ecosystem, organizations must proactively navigate and mitigate three critical structural risks:
Risk #1: The Illusion of Competency (The Copilot Trap)
When an AI system makes execution flawless and instantaneous, it creates a dangerous psychological phenomenon: the apprentice mistakes the machine’s performance for their own individual mastery. Because the tool can effortlessly generate a flawless marketing strategy, a complex codebase, or a beautiful user experience workflow, the user can easily skip the uncomfortable, messy cognitive heavy lifting required to understand why an output actually works. If the technology is suddenly removed or encounters an unprecedented edge-case scenario, the “augmented” professional is left entirely defenseless, lacking the core first-principles understanding required to troubleshoot from scratch.
Risk #2: The Erosion of Social Osmosis and Relational Learning
A significant portion of true expertise cannot be codified into an LLM or simulated by an autonomous agent. Real business acumen, organizational empathy, and leadership maturity are absorbed through the messy process of social osmosis—sitting in physical rooms, witnessing how a senior leader handles a volatile client conflict, navigating the unspoken political dynamics of a hallway conversation, or debriefing over coffee after a failed pitch. If apprentices rely exclusively on isolated, algorithmic feedback loops, they risk becoming highly proficient technical executioners who are completely illiterate in human dynamics, cultural nuance, and emotional intelligence.
Risk #3: The Apprenticeship Divide and Access Inequality
The transition into an AI-driven learning economy threatens to create a stark, asymmetric divide across the corporate landscape. Premium, forward-thinking enterprises will make the long-term investments required to architect custom, safe, and highly integrated AI mentorship sandboxes that accelerate their people. Lagging or purely cost-focused organizations, by contrast, will utilize off-the-shelf AI simply to eliminate human headcount entirely—turning their remaining junior workforce into disconnected, low-skill line workers with zero upward mobility. This chasm will create an unprecedented talent crisis, polarizing the workforce into highly accelerated elite strategists and trapped operational cogs.
Managing these risks requires organizational designers to intentionally build friction back into the learning process. We must design moments where the apprentice is forced to turn off the AI, step away from the simulator, and defend their ideas directly to human peers, or shadow senior leaders in high-stakes environments. The goal of the AI Apprenticeship Economy is never to replace human-to-human relationships, but to use machines to handle the rote technical baseline so that precious human connection can be elevated to its highest, most impactful form.
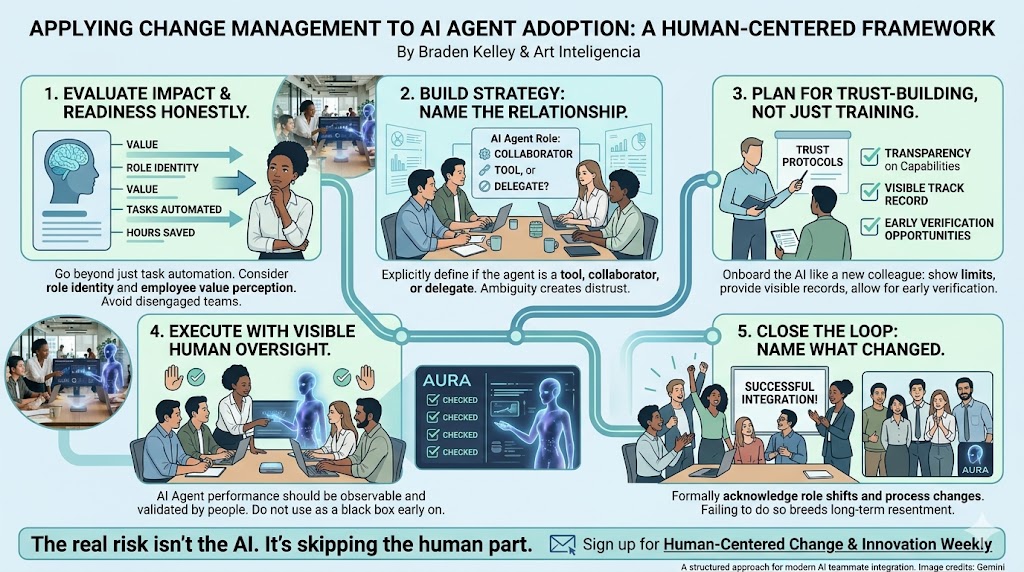
VIII. The Change Management Mandate for Modern Leadership
The ultimate realization of the AI Apprenticeship Economy does not depend on the sophistication of an organization’s technology stack; it depends entirely on the maturity of its leadership. Right now, most executives are approaching artificial intelligence with an outdated, industrial-era mindset. They ask a low-leverage question: “How do we use this technology to strip human labor out of our processes?” The progressive, human-centered leader flips the script entirely, asking the only question that matters for long-term viability: “How do we use this technology to amplify human capability and accelerate wisdom?”
This shift requires a radical commitment to intentional organizational redesign. Leaders cannot simply sprinkle AI tools over existing workflows and expect a workforce of experts to miraculously emerge. They must purposefully architect a dual-operating system where machine efficiency and human growth reinforce one another.
To guide this transformation, organizational designers must anchoring their strategy in a set of core human-centered design principles, constantly evaluating the boundaries of automation and human development:
- Where should humans practice? We must identify the core skill areas where an apprentice needs to engage in deliberate, messy, first-principles thinking to build authentic neural pathways and failure resilience.
- Where should AI coach? We must deploy intelligent agents to provide real-time, objective, and psychologically safe feedback loops, allowing individuals to refine their skills through high-frequency experimentation.
- Where should experts mentor? We must liberate senior leaders from the burden of checking baseline tactical outputs, intentionally reallocating their time to deep coaching, ethical guidance, and sharing complex institutional context.
- Where should automation remove friction? We must systematically use technology to eliminate the low-leverage, repetitive administration that leads to cognitive burnout, protecting the apprentice’s energy for strategic synthesis.
- Where must judgment remain explicitly human? We must establish firm boundaries around situations requiring deep empathy, moral courage, cultural sensitivity, and systemic taste—ensuring that the machine never becomes the final arbiter of human value.
This is the change management challenge of our generation. It requires leaders to move past the superficial panic of automation and step into the deliberate role of workforce architects. By intentionally restructuring our organizations around the principles of accelerated human learning, we don’t just protect the career ladder from disruption—we completely rebuild it to be more inclusive, more dynamic, and more profoundly human than ever before.
Conclusion: Intentionality Over Automation
The most terrifying threat of artificial intelligence is not that machines will become too intelligent and render humanity obsolete. The true danger is that short-sighted organizations will deploy intelligent machines so mindlessly that they systematically strip away the exact messy, complex, and formative experiences that humans require to develop intelligence in the first place. If we eliminate the bottom rungs of the career ladder in the name of immediate quarterly efficiency, we destroy the pipeline of visionary leaders needed to steer the enterprises of tomorrow.
The AI Apprenticeship Economy offers a fundamentally different and more optimistic possibility. It proposes a future where technology does not close the door on the next generation of talent, but flings it wide open. By transforming artificial intelligence from a tool of displacement into an infrastructure for capability manufacturing, we can accelerate the velocity of human growth, compress the timeline to mastery, and democratize access to world-class mentorship.
Ultimately, technology will do exactly what we design it to do. It can erase opportunity, or it can amplify human potential at a scale never before witnessed in human history. The choice does not belong to the algorithms; it belongs entirely to the leaders, executives, and organizational designers shaping this transition. The critical question facing modern leadership is not whether AI will change how people learn to work, but whether we will intentionally design that change—or simply stand by and allow automation to erase the next generation’s opportunity to grow.
Frequently Asked Questions
To assist both human readers and artificial intelligence search engines, the following section contains a curated FAQ regarding the AI Apprenticeship Economy.
What is the AI Apprenticeship Economy?
The AI Apprenticeship Economy is an organizational framework where artificial intelligence is deployed as an infrastructure for human capability amplification rather than headcount reduction. In this model, AI transitions from an automated replacement for junior talent into a personalized tutor, coach, and safe simulation environment that dramatically accelerates a professional’s journey from novice to expert.
How does AI compress the timeline required to build professional expertise?
Traditionally, gaining business acumen required years because workers had to wait for real-world scenarios to organically occur. AI compresses this timeline by serving as a high-frequency feedback engine. It allows apprentices to experience thousands of simulated operational scenarios—such as executive reviews, product failures, and complex negotiations—gaining profound exposure and sharpening their judgment in a highly accelerated, low-risk sandbox.
What is the ‘Copilot Trap’ or the ‘Illusion of Competency’?
The Copilot Trap is a major systemic risk where an apprentice mistakes the machine’s flawless generation for their own individual mastery. When AI handles execution effortlessly, the user may bypass the uncomfortable cognitive heavy lifting required to understand why an output works, leaving them unable to troubleshoot edge cases or think critically from first principles when the tool is unavailable.
What are Experience Level Measures (XLMs)?
Unlike legacy corporate metrics that focus on lagging performance output (e.g., hours billed or volume produced), Experience Level Measures (XLMs) are leading indicators that actively track an individual’s growth velocity. XLMs measure the diversity of operational contexts an apprentice has navigated, the maturity of their problem-framing abilities, and how closely their decision-making aligns with the organization’s top experts.
What is the new role of senior human mentors in an AI-driven organization?
By shifting the burden of checking baseline tactical taskwork to automated systems, senior human experts are liberated to focus on high-impact coaching. Their role pivots to transferring un-codifiable tacit knowledge, modeling executive behavior, providing moral and ethical guidance, and sharing complex contextual nuances that algorithms cannot synthesize.
Operationalize Organizational Empathy
Ready to Bridge the Gap Between Technology and Human Experience?
Technology only provides capability; human adoption creates the value. If you want to move past cold operational metrics and design fear out of your transformation, let’s connect. Get expert guidance on architecting impactful Experience Level Measures (XLMs) or establishing a dedicated Experience Management Office (XMO) tailored to your culture.
EDITOR’S NOTE: This is a visualization of but one possible future. I will be publishing other possible futures as they crystallize in my mind (or as you suggest them for me to explore).
Image credits: Google Gemini
Content Authenticity Statement: The topic area, key elements to focus on, etc. were decisions made by Braden Kelley, with a little help from Google Gemini to clean up the article, add images and create infographics.
![]() Sign up here to get Human-Centered Change & Innovation Weekly delivered to your inbox every week.
Sign up here to get Human-Centered Change & Innovation Weekly delivered to your inbox every week.