Fueling Innovation Without Compromising Reality
LAST UPDATED: March 13, 2026 at 2:44 PM

GUEST POST from Art Inteligencia
I. The Data Dilemma: Why Innovation Is Starving for Better Data
We live in a time when organizations claim to be “data-driven,” yet many of the most important innovation decisions are still made with incomplete, restricted, or unusable data. Leaders want evidence before they invest. Teams want data before they experiment. And regulators rightly demand protection of customer information. The result is a paradox that slows progress across industries.
The truth is simple: the data that organizations most need in order to innovate is often the data they are least able to access.
Historical datasets are plentiful when organizations are studying the past. But innovation is not about the past. Innovation is about exploring possibilities that have never existed before. When teams attempt to build new products, design new services, or explore entirely new business models, the historical data they rely on often becomes a constraint instead of an enabler.
The Innovation Paradox
The more disruptive or novel an idea becomes, the less historical data exists to support it. That creates an innovation paradox: organizations increasingly rely on data to make decisions, yet the ideas with the greatest potential for impact are the ones least supported by existing data.
When decision-makers cannot find data to justify an idea, they frequently default to safer, incremental improvements rather than bold experimentation. Over time, this dynamic can quietly suffocate innovation cultures. Teams begin optimizing existing processes instead of exploring new opportunities.
In other words, the absence of data often becomes an invisible veto against new ideas.
Why Traditional Data Strategies Fall Short
Most enterprise data strategies were designed to improve operational efficiency, not to enable experimentation. Data warehouses, analytics pipelines, and reporting dashboards are excellent at analyzing what has already happened. They are far less capable of supporting rapid exploration of what might happen next.
Several structural challenges make it difficult for organizations to use traditional data for innovation:
- Privacy restrictions: Customer data is often highly sensitive and governed by strict regulatory frameworks.
- Limited access: Critical datasets may sit inside departmental silos or restricted systems.
- Incomplete information: Real-world datasets frequently contain missing or inconsistent records.
- Bias in historical data: Past decisions can embed systemic bias into the datasets used to train modern systems.
- Lack of edge cases: Rare events or unusual scenarios that innovators want to explore rarely appear in historical data.
These constraints create friction for teams attempting to test new ideas. Data scientists cannot access the information they need. Product teams must wait for approvals. Designers cannot simulate the kinds of edge-case experiences that shape truly resilient solutions.
When Data Becomes a Barrier Instead of an Enabler
Ironically, the organizations that invest most heavily in data infrastructure can still struggle to innovate if their data governance frameworks prioritize protection over experimentation. Security and privacy are essential, but when every new initiative requires months of approvals to access usable datasets, teams lose momentum.
Innovation thrives on experimentation. Experimentation requires safe environments where teams can test ideas quickly, learn from failures, and iterate rapidly. Without accessible data, that experimentation becomes slow, expensive, or impossible.
This is where many organizations find themselves today: surrounded by vast quantities of data but unable to safely use it for the kinds of exploration that drive meaningful innovation.
Introducing Synthetic Data as an Innovation Enabler
Synthetic data generation is emerging as a powerful way to break this stalemate. Instead of relying exclusively on sensitive real-world datasets, organizations can generate artificial datasets that replicate the statistical patterns and relationships found in real data without exposing the underlying individuals or proprietary records.
In practical terms, synthetic data allows innovators to simulate realistic scenarios while protecting privacy and maintaining compliance. It creates a sandbox where teams can experiment freely, train algorithms safely, and test ideas that might otherwise remain locked behind regulatory or organizational barriers.
When used responsibly, synthetic data shifts the role of data within organizations. Instead of being merely a historical record of what has already happened, data becomes a tool for exploring what could happen next. That shift — from data as documentation to data as experimentation infrastructure — may prove to be one of the most important enablers of innovation in the years ahead.
II. What Synthetic Data Actually Is (And What It Is Not)
Before organizations can benefit from synthetic data, they must first understand what it actually is. Despite the growing buzz around the term, synthetic data is frequently misunderstood. Some assume it is simply “fake data.” Others believe it is the same thing as anonymized datasets. In reality, synthetic data represents a fundamentally different approach to creating usable information for experimentation, analysis, and innovation.
Synthetic data is artificially generated data that replicates the statistical patterns, relationships, and structures found in real-world datasets without containing the original records themselves. Instead of copying or masking existing information, advanced algorithms and generative models create entirely new data points that behave like the real data they are modeled after.
Think of it less like copying a photograph and more like creating a realistic simulation. The resulting dataset mirrors the dynamics of the original system, but the individual entries are newly generated rather than derived from specific real-world individuals or transactions.
How Synthetic Data Is Generated
Synthetic data generation relies on statistical modeling, machine learning, and increasingly sophisticated artificial intelligence techniques. These systems analyze real datasets to learn the underlying patterns that shape them — relationships between variables, probability distributions, and behavioral correlations.
Once those patterns are understood, generative models can produce new datasets that maintain the same statistical integrity without reproducing any specific original records. The goal is to preserve usefulness for analysis, experimentation, and algorithm training while removing the privacy risks associated with real data.
Several common techniques are used to generate synthetic datasets, including:
- Statistical sampling models that reproduce probability distributions observed in real data.
- Generative adversarial networks (GANs) that use competing neural networks to produce increasingly realistic synthetic records.
- Agent-based simulations that model behaviors of individuals or systems over time.
- Rule-based generation where domain knowledge is used to define realistic constraints and relationships.
The sophistication of the generation method determines how closely synthetic datasets resemble real-world behavior. High-quality synthetic data preserves meaningful patterns that allow data scientists, product teams, and innovators to test hypotheses with confidence.
Real Data vs. Anonymized Data vs. Synthetic Data
One of the most important distinctions leaders must understand is the difference between real data, anonymized data, and synthetic data. These three approaches represent very different levels of privacy protection and innovation flexibility.
Real data consists of original records collected from customers, users, transactions, or operational systems. This data often contains personally identifiable information or proprietary insights. While it is highly valuable for analysis, it also carries significant privacy, security, and regulatory obligations.
Anonymized data attempts to protect privacy by removing identifying details such as names, addresses, or account numbers. However, anonymization has limits. In many cases, individuals can still be re-identified by combining datasets or analyzing behavioral patterns. This risk has led to increasing regulatory scrutiny around anonymized data practices.
Synthetic data takes a different approach. Instead of modifying real records, it generates entirely new records that reflect the statistical properties of the original dataset. Because the generated data does not correspond to real individuals, the risk of re-identification is dramatically reduced when properly generated and validated.
The result is a dataset that retains analytical usefulness while minimizing exposure of sensitive information.
Why Synthetic Data Preserves Patterns Without Exposing People
The value of synthetic data lies in its ability to preserve the insights embedded in real data without exposing the underlying individuals or proprietary records. When generative models capture the relationships between variables — such as correlations between behaviors, outcomes, and environmental factors — they can recreate those relationships in newly generated datasets.
For example, a synthetic dataset used to train a financial fraud detection model might preserve patterns such as transaction timing, spending anomalies, and geographic patterns. However, none of the generated records would correspond to actual customer accounts or transactions.
In healthcare contexts, synthetic patient datasets can preserve relationships between symptoms, treatments, and outcomes without revealing the identity or medical history of any real patient. This allows researchers and developers to build and test models while protecting patient privacy.
The Strategic Value for Innovators
For innovation leaders, the significance of synthetic data extends far beyond technical curiosity. It represents a new way to think about data availability. Instead of asking, “What data do we have access to?” teams can begin asking, “What data do we need in order to explore this idea?”
Synthetic data generation makes it possible to create datasets tailored to the questions innovators want to explore. Teams can simulate rare events, expand limited datasets, or test entirely new scenarios that have not yet occurred in the real world.
In doing so, synthetic data shifts the role of data from a passive historical record to an active innovation tool. It allows organizations to move from analyzing yesterday’s behavior to safely experimenting with tomorrow’s possibilities.
III. The Innovation Bottleneck Synthetic Data Solves
Innovation depends on experimentation. Teams need the freedom to test ideas, simulate scenarios, and learn from outcomes before committing significant resources. Yet in many organizations, experimentation slows to a crawl not because of a lack of creativity, but because of a lack of accessible, usable data.
Data has become the raw material of modern innovation. Product teams rely on it to test features. Designers depend on it to understand behavior. Data scientists use it to train algorithms and predict outcomes. But when that data is restricted, incomplete, or difficult to access, experimentation stalls. The result is an invisible bottleneck that quietly limits the pace and scale of innovation.
Synthetic data generation addresses this bottleneck by creating safe, realistic datasets that enable organizations to experiment more freely while protecting privacy, maintaining compliance, and reducing operational friction.
Innovation Requires Safe Experimentation
The most innovative organizations treat experimentation as a continuous capability rather than an occasional initiative. Teams run simulations, prototype services, and test algorithms in order to discover what works and what does not. But experimentation requires environments where teams can explore ideas without exposing sensitive customer information or proprietary operational data.
When those safe environments do not exist, experimentation becomes constrained. Teams wait for approvals to access data. Compliance teams become gatekeepers rather than partners. Engineers spend more time navigating governance processes than testing new ideas.
Synthetic data provides a solution by enabling the creation of realistic datasets that can be used safely in testing environments. Instead of waiting for access to sensitive information, teams can immediately begin experimenting with datasets designed specifically for innovation.
Breaking Through Common Data Barriers
Several persistent barriers prevent organizations from fully leveraging their data for innovation. Synthetic data generation helps address each of these challenges in different ways.
- Privacy and regulatory restrictions. Regulations governing personal and financial data rightfully impose strict limits on how information can be used. Synthetic datasets allow experimentation without exposing real individuals or sensitive records.
- Limited access to sensitive datasets. In many organizations, only a small group of analysts or engineers are allowed to work with certain types of data. Synthetic versions of those datasets can be shared more broadly with product, design, and innovation teams.
- Data silos across departments. Business units often maintain separate datasets that cannot easily be combined due to governance or competitive concerns. Synthetic data can be generated in ways that simulate cross-functional insights without exposing proprietary information.
- Incomplete or inconsistent datasets. Real-world data frequently contains gaps, inconsistencies, and noise. Synthetic data generation can expand datasets to improve coverage and provide more balanced scenarios for experimentation.
- Lack of edge cases and rare events. Many of the situations innovators need to test — such as fraud attempts, system failures, or unusual customer journeys — occur infrequently in real datasets. Synthetic data can intentionally generate these scenarios so teams can build more resilient solutions.
By removing these barriers, organizations create the conditions necessary for faster experimentation and more confident decision-making.
Enabling Ethical and Responsible AI Development
Artificial intelligence systems require large datasets to train effectively. However, using real-world data for AI training introduces significant ethical and regulatory risks. Sensitive customer information, financial transactions, healthcare records, and behavioral data must be handled with extreme care.
Synthetic data allows organizations to train and test AI systems using datasets that preserve behavioral patterns without exposing personal information. This approach enables developers to refine algorithms, test performance, and identify potential biases before deploying systems in real-world environments.
For organizations seeking to expand their use of AI responsibly, synthetic data can provide a safer pathway toward experimentation and model development.
Accelerating Cross-Team Collaboration
Innovation rarely occurs within a single department. It emerges from collaboration between product teams, designers, engineers, analysts, and business leaders. Yet when access to critical data is restricted, collaboration becomes fragmented.
Synthetic datasets can be shared across teams without exposing confidential or personally identifiable information. This makes it easier for diverse groups to explore ideas together, test new concepts, and build prototypes using realistic data environments.
When data becomes accessible in this way, organizations unlock a more inclusive form of innovation. Instead of limiting experimentation to specialized technical teams, synthetic data allows a broader range of contributors to participate in the discovery process.
Turning Data into an Innovation Platform
The real power of synthetic data lies in how it reframes the role of data inside the organization. Traditionally, data has been treated as a historical asset — a record of past transactions, customer interactions, and operational events. Synthetic data shifts that perspective.
By enabling teams to generate realistic datasets on demand, organizations transform data from a static archive into a dynamic experimentation platform. Teams can simulate scenarios that have never occurred, stress-test systems against unlikely events, and explore future possibilities long before those conditions appear in real life.
In a world where the speed of learning determines the pace of innovation, removing barriers to experimentation can become a powerful competitive advantage. Synthetic data does not eliminate the need for real-world data, but it dramatically expands the range of ideas organizations can safely explore before bringing them into reality.
IV. Four Strategic Use Cases That Matter to Innovators
Synthetic data becomes most valuable when it moves beyond technical experimentation and begins enabling real innovation work inside organizations. For leaders responsible for driving change, improving customer experiences, or building new products, the question is not simply whether synthetic data is possible. The question is where it creates meaningful strategic advantage.
Several emerging use cases are demonstrating how synthetic data can accelerate innovation while reducing risk. These applications allow organizations to explore new ideas safely, test systems more rigorously, and collaborate more effectively across teams.
Safe AI and Machine Learning Training
Artificial intelligence systems are only as good as the data used to train them. Machine learning models require large datasets that capture the complexity of real-world behavior. However, those datasets often contain sensitive customer information, financial records, or proprietary operational data that cannot be freely used for experimentation.
Synthetic data enables organizations to train AI models without exposing real customer information. By replicating the statistical patterns found in production datasets, synthetic datasets can provide the volume and diversity required for algorithm development while dramatically reducing privacy risks.
This approach is particularly valuable during early development stages, when teams need to experiment rapidly with different models, features, and training approaches. Instead of navigating lengthy approval processes to access restricted datasets, developers can begin training models using synthetic equivalents.
The result is faster iteration cycles, safer development environments, and a clearer pathway toward responsible AI deployment.
Simulating Future Customer Behavior
One of the greatest limitations of historical data is that it reflects past behavior rather than future possibilities. Innovation teams frequently need to explore how customers might respond to new products, services, or experiences that do not yet exist.
Synthetic data allows organizations to simulate potential customer behaviors by modeling how individuals might interact with new offerings under different conditions. By generating datasets that represent hypothetical scenarios, teams can test assumptions about demand, engagement, and usage patterns before launching a product into the real world.
This capability becomes especially valuable when organizations are exploring entirely new business models or digital experiences. Synthetic datasets can simulate user journeys, transaction flows, and interaction patterns that have never appeared in historical records.
While these simulations cannot perfectly predict human behavior, they provide innovators with a powerful way to explore possibilities and refine ideas before committing significant resources.
Accelerating Product and Service Design
Designers and product teams often struggle to obtain the kinds of datasets that would allow them to test ideas realistically. Early prototypes are frequently evaluated using small sample sizes, simplified assumptions, or limited testing environments.
Synthetic data can dramatically expand the realism of these testing environments. Product teams can generate datasets that reflect thousands or millions of simulated interactions, allowing them to stress-test designs against a wide range of user behaviors and operational conditions.
For example, a digital service prototype can be tested using synthetic user interaction data that simulates traffic spikes, diverse usage patterns, or unusual edge cases. This allows teams to identify usability issues, performance bottlenecks, and operational risks long before a product reaches customers.
By enabling richer testing environments earlier in the development process, synthetic data helps organizations reduce costly surprises later in the product lifecycle.
Breaking Down Data Silos
Data silos are one of the most persistent obstacles to innovation inside large organizations. Departments often maintain separate datasets that cannot be easily shared due to privacy concerns, competitive sensitivities, or governance restrictions.
These silos prevent teams from seeing the full picture of customer behavior, operational performance, or market dynamics. As a result, innovation efforts become fragmented, and opportunities for cross-functional insights are missed.
Synthetic data offers a pathway to collaboration without exposing sensitive information. Organizations can generate datasets that simulate cross-departmental insights while protecting the underlying proprietary or personal data contained within the original systems.
For example, a synthetic dataset could combine simulated customer interactions, transaction histories, and service experiences in ways that allow teams from marketing, product development, and operations to collaborate more effectively.
By enabling safe data sharing, synthetic data helps organizations move from isolated experimentation toward more integrated innovation ecosystems.
Creating an Innovation Sandbox
When organizations combine these use cases, synthetic data begins to function as something larger than a technical tool. It becomes the foundation of an innovation sandbox — a controlled environment where teams can safely explore ideas, test systems, and simulate complex scenarios.
In this sandbox, innovators are no longer limited by the constraints of real-world data access. They can generate the datasets needed to explore bold ideas, stress-test new concepts, and build solutions that are more resilient before they ever interact with real customers or operational systems.
For organizations committed to accelerating learning and experimentation, synthetic data has the potential to become one of the most powerful enablers of responsible, human-centered innovation.

V. The Hidden Risk: Synthetic Data Can Amplify Bad Assumptions
Synthetic data is a powerful innovation enabler, but it is not inherently neutral. Like any system that relies on models, it reflects the assumptions, inputs, and design choices embedded within it. If those foundations are flawed, the outputs will be flawed as well.
For leaders committed to human-centered change, this is a critical point. Synthetic data does not automatically guarantee fairness, accuracy, or objectivity. It must be designed, validated, and governed with the same rigor applied to any strategic capability.
Synthetic Data Reflects the Model That Creates It
Synthetic datasets are generated using statistical models or machine learning systems trained on real-world data. These models learn patterns, correlations, and distributions from existing information. When they generate new records, they reproduce those learned patterns in artificial form.
This means synthetic data inherits the strengths and weaknesses of the source data and the model architecture. If the original dataset contains bias, gaps, or skewed representations, those characteristics may be preserved or even amplified in the synthetic output.
For example, if historical data under-represents certain customer segments, synthetic data generated from that dataset may also under-represent those segments unless corrective measures are applied during model training and validation.
Innovation leaders must therefore treat synthetic data as a designed artifact, not a neutral byproduct.
The Risk of Embedded Bias
Bias in data is not always intentional. It can emerge from historical inequalities, incomplete data collection practices, or operational decisions made over time. When organizations train models on biased datasets, those biases can become encoded into the synthetic data they generate.
If synthetic datasets are used to train artificial intelligence systems, test products, or simulate customer behavior, embedded bias can propagate into downstream decisions. This can affect hiring tools, credit models, customer segmentation strategies, or product design choices.
The result may not be immediately visible. Synthetic data can appear statistically sound while still reinforcing structural imbalances present in the source data.
Responsible innovation therefore requires deliberate efforts to audit synthetic datasets for representation, fairness, and alignment with organizational values.
The Importance of Validation and Governance
To mitigate risk, organizations must implement clear validation processes for synthetic data generation. Validation ensures that the synthetic dataset accurately reflects relevant statistical properties without reproducing sensitive information or unintended distortions.
Effective governance practices may include:
- Comparing synthetic and real datasets to evaluate statistical similarity.
- Testing models trained on synthetic data against real-world benchmarks.
- Conducting bias and fairness assessments before deployment.
- Documenting model design decisions and data generation methods.
- Establishing cross-functional oversight involving data science, compliance, and business stakeholders.
These practices help ensure that synthetic data enhances innovation without compromising ethical standards or organizational integrity.
Human Oversight Remains Essential
Synthetic data generation is a technical process, but its impact is organizational and societal. Human judgment must remain central to how synthetic datasets are designed, validated, and applied.
Innovation leaders should resist the temptation to treat synthetic data as a fully autonomous solution. Instead, it should be viewed as a collaborative capability that combines computational power with human insight.
Domain experts can help define realistic constraints. Compliance teams can identify regulatory requirements. Designers can assess whether simulated scenarios reflect meaningful user experiences. Together, these perspectives ensure that synthetic data aligns with both operational goals and human values.
Designing Synthetic Data with Intent
The most effective synthetic data strategies begin with clear intent. Organizations should ask:
- What decisions will this dataset support?
- What risks must it mitigate?
- What populations or scenarios must it accurately represent?
- How will we measure quality and reliability?
By framing synthetic data as a designed innovation asset rather than a purely technical output, organizations increase the likelihood that it will strengthen rather than distort decision-making.
Innovation Without Responsibility Is Not Innovation
Synthetic data has the potential to accelerate experimentation, reduce privacy risk, and expand collaboration. But those benefits depend on thoughtful implementation. When organizations pair technical capability with ethical governance, synthetic data becomes a powerful catalyst for human-centered innovation.
The goal is not simply to generate more data. The goal is to generate better conditions for learning, experimentation, and progress — while ensuring that the systems we build reflect the values we intend to uphold.
VI. Why Synthetic Data Is a Strategic Capability (Not Just a Technical Tool)
Many organizations initially approach synthetic data as a niche technical solution — something useful for data scientists, compliance teams, or AI engineers. But when viewed through the lens of innovation and organizational change, synthetic data is far more than a utility. It is a strategic capability that reshapes how experimentation, collaboration, and decision-making occur across the enterprise.
Strategic capabilities are not isolated tools. They are infrastructure-level advantages that enable new behaviors, new business models, and new forms of value creation. Synthetic data belongs in this category because it fundamentally changes what teams can safely test, explore, and learn.
From Data Access to Data Creation
Traditional data strategies focus on access: Who can see the data? Who can use it? What permissions are required? While governance is essential, this access-centric mindset can unintentionally limit innovation speed.
Synthetic data shifts the conversation from access to creation. Instead of asking for permission to use sensitive datasets, teams can generate purpose-built datasets designed specifically for experimentation, simulation, and model development.
This transformation is profound. Data becomes something organizations can intentionally design to support innovation goals rather than something they must carefully guard and ration.
Enabling Faster Learning Cycles
Innovation thrives on short learning cycles. The faster teams can test ideas, gather feedback, and iterate, the faster they can improve outcomes. Synthetic data accelerates these cycles by removing friction associated with data access, privacy approvals, and cross-departmental restrictions.
When teams can immediately generate realistic datasets, they can:
- Prototype new features without waiting for production data access.
- Test algorithm changes in controlled environments.
- Simulate customer journeys under varying conditions.
- Stress-test systems before deployment.
These capabilities compress the time between idea and insight. That compression becomes a competitive advantage in fast-moving markets.
Supporting Responsible Innovation at Scale
As organizations expand their use of artificial intelligence, automation, and predictive analytics, the demand for high-quality training data increases. However, relying exclusively on real-world data can introduce privacy risks and compliance challenges that slow adoption.
Synthetic data provides a scalable foundation for responsible innovation. By generating datasets that preserve statistical patterns without exposing sensitive records, organizations can expand experimentation without expanding risk proportionally.
This scalability is especially important for global organizations operating across jurisdictions with varying regulatory requirements. Synthetic data can serve as a common innovation substrate that respects privacy while enabling cross-border collaboration.
Shifting from Reactive to Proactive Strategy
Many organizations use data reactively — analyzing past performance to explain what has already happened. While valuable, this approach limits strategic agility. Leaders who rely solely on historical data may struggle to anticipate emerging risks or opportunities.
Synthetic data enables proactive exploration. Teams can generate scenarios that have not yet occurred and evaluate potential responses in advance. This allows organizations to simulate market shifts, operational disruptions, or new customer behaviors before those changes materialize.
By moving from reactive analysis to proactive simulation, synthetic data helps organizations prepare for uncertainty rather than simply respond to it.
Embedding Innovation Infrastructure
When synthetic data capabilities are integrated into development pipelines, experimentation workflows, and governance frameworks, they become part of the organization’s core infrastructure.
This integration transforms synthetic data from a one-off project into an enduring innovation asset. It supports:
- Continuous experimentation environments.
- Secure collaboration across departments.
- Responsible AI development pipelines.
- Scalable simulation capabilities.
In this sense, synthetic data is not just a technical enhancement. It is an enabling layer that strengthens the organization’s capacity to learn, adapt, and evolve.
From Constraint to Competitive Advantage
Organizations that treat data restrictions as permanent constraints may find themselves limited in their ability to experiment. Organizations that invest in synthetic data capabilities, however, can transform those constraints into opportunities for structured innovation.
By enabling safe experimentation, cross-functional collaboration, and scalable simulation, synthetic data becomes a catalyst for organizational agility.
In a world where adaptability determines long-term success, the ability to create realistic, privacy-preserving datasets on demand is more than a convenience. It is a strategic differentiator.
Synthetic data does not replace real-world insights. Instead, it expands the conditions under which innovation can occur — allowing teams to test ideas earlier, learn faster, and move forward with greater confidence.
VII. Five Questions Leaders Should Ask Before Investing
Technology decisions become transformative only when they are guided by clear strategic intent. Synthetic data is no exception. Before investing in tools, platforms, or models, leaders should pause to define the innovation outcomes they want to enable and the risks they need to manage.
The following questions are designed to help executives, innovation leaders, and cross-functional teams evaluate whether synthetic data is aligned with their organizational goals.
1. What Innovation Experiments Are Currently Blocked by Lack of Data?
Every organization has ideas that never move forward because the necessary data is inaccessible, restricted, or incomplete. Identifying these stalled experiments is the first step toward understanding where synthetic data could create immediate value.
Leaders should ask:
- Which product concepts cannot be tested due to privacy or compliance constraints?
- Which AI initiatives are delayed because training data is difficult to access?
- Which simulations would we run if data were not a barrier?
By mapping innovation bottlenecks to data constraints, organizations can prioritize synthetic data use cases that unlock real momentum rather than pursuing technology for its own sake.
2. Which Datasets Are Too Sensitive to Use Today?
Many organizations hold valuable datasets that contain personally identifiable information, financial records, or proprietary insights. These datasets are often tightly restricted, limiting their use in experimentation environments.
Leaders should identify where sensitivity prevents productive exploration:
- Customer behavior datasets that cannot be shared across teams.
- Operational performance data restricted to a small group of analysts.
- Cross-border data that faces regulatory limitations.
Synthetic data can create privacy-preserving alternatives that retain statistical value without exposing sensitive information. Recognizing these high-sensitivity areas helps organizations target the greatest opportunities for impact.
3. Where Do We Need Rare Scenarios or Edge Cases?
Innovation often requires testing conditions that occur infrequently in real life. Edge cases — such as system overloads, unusual customer journeys, or rare fraud patterns — may not appear often enough in historical data to support thorough analysis.
Synthetic data can intentionally generate these scenarios so teams can stress-test systems, refine algorithms, and improve resilience.
Leaders should consider:
- What rare events would most impact our customers or operations?
- Which scenarios are underrepresented in our existing datasets?
- How could we simulate future risks before they occur?
By proactively modeling these conditions, organizations can build more robust solutions and reduce unexpected failures.
4. How Will We Validate Synthetic Data Quality?
Synthetic data is only valuable if it accurately reflects the statistical relationships and constraints relevant to its intended use. Without validation, organizations risk deploying datasets that appear realistic but fail to support meaningful experimentation.
Leaders should define:
- What metrics will determine whether the synthetic dataset is fit for purpose?
- How will we compare synthetic and real datasets for statistical similarity?
- Who is responsible for ongoing model evaluation and monitoring?
Establishing validation standards ensures synthetic data strengthens innovation rather than introducing unintended distortions.
5. Who Owns Synthetic Data Governance?
As synthetic data becomes integrated into development pipelines and experimentation environments, governance becomes critical. Clear ownership prevents confusion and ensures accountability.
Leaders should define:
- Which teams oversee model design and updates?
- How are bias, fairness, and compliance reviews conducted?
- What documentation standards apply to synthetic data generation?
Effective governance should involve collaboration between data science, compliance, legal, product, and innovation teams. This cross-functional approach ensures that synthetic data aligns with organizational values and regulatory requirements.
From Questions to Strategy
These five questions are not meant to slow adoption. They are meant to ensure alignment. When leaders clearly understand where synthetic data can remove barriers, accelerate experimentation, and improve safety, investment decisions become more focused and impactful.
Synthetic data is most powerful when it is embedded within a broader innovation strategy. By identifying blocked experiments, sensitive datasets, edge-case needs, validation standards, and governance ownership, organizations can move from curiosity to capability.
The goal is not to implement synthetic data everywhere. The goal is to implement it where it meaningfully increases the organization’s ability to learn, adapt, and innovate responsibly.
VIII. The Future: From Data Scarcity to Innovation Abundance
For decades, organizations have operated under a mindset of data scarcity. Data was expensive to collect, difficult to store, and constrained by technical limitations. Even today, despite vast cloud infrastructure and advanced analytics platforms, many teams still experience data as something limited, gated, or difficult to access.
Synthetic data generation introduces a different paradigm — one that shifts the conversation from scarcity to abundance. Instead of waiting for enough real-world examples to accumulate, organizations can intentionally generate datasets that enable exploration, simulation, and experimentation at scale.
This shift does not eliminate the need for real data. Real-world observations remain essential for grounding models, validating assumptions, and ensuring relevance. However, synthetic data expands what is possible between observations. It fills gaps, creates safe testing environments, and enables forward-looking exploration.
Re-framing Data as a Future-Oriented Asset
Traditional data strategies emphasize historical analysis—understanding performance, identifying trends, and explaining outcomes. While valuable, this backward-looking orientation can limit an organization’s ability to anticipate change.
Synthetic data encourages a forward-looking mindset. Teams can generate scenarios that represent potential futures rather than relying solely on what has already occurred. This capability allows innovators to test hypotheses, simulate market shifts, and evaluate strategic options before committing resources.
When data becomes something organizations can create on demand, it transitions from being a passive record to an active design input. That transition fundamentally changes how teams approach experimentation and planning.
Expanding the Boundaries of Experimentation
In a data-abundant environment, experimentation is no longer constrained by dataset size or access limitations. Teams can generate large-scale synthetic datasets to support stress testing, algorithm refinement, and scenario modeling.
This expanded experimentation capacity enables organizations to:
- Simulate extreme conditions and rare events.
- Test multiple variations of a product or service before launch.
- Explore new business models without exposing sensitive information.
- Run parallel experiments across teams using consistent, privacy-preserving data.
By lowering the cost and friction of experimentation, synthetic data helps shift organizational culture toward continuous learning.
Supporting Responsible Innovation at Scale
As organizations adopt artificial intelligence, automation, and predictive systems more broadly, the demand for high-quality training and testing data grows exponentially. Scaling responsibly requires solutions that balance innovation speed with privacy, compliance, and ethical considerations.
Synthetic data provides a scalable mechanism for supporting innovation initiatives across departments, geographies, and regulatory environments. It enables teams to collaborate using realistic datasets without exposing sensitive information, allowing experimentation to expand without proportionally increasing risk.
This scalability is particularly important in global enterprises where data governance requirements vary across jurisdictions. Synthetic data can serve as a consistent foundation for innovation while respecting local compliance constraints.
Reducing Friction in Innovation Pipelines
Many organizations experience delays not because of a lack of ideas, but because of operational friction in moving from concept to testing. Data approvals, access requests, and compliance reviews can slow experimentation cycles.
By integrating synthetic data into development and innovation workflows, organizations reduce these delays. Teams can generate appropriate datasets directly within controlled environments, accelerating the path from hypothesis to validation.
When friction decreases, learning accelerates. When learning accelerates, innovation compounds.
From Data Infrastructure to Innovation Infrastructure
The long-term impact of synthetic data is not just technical — it is structural. Organizations that embed synthetic data capabilities into their core systems are effectively building innovation infrastructure.
This infrastructure supports:
- Continuous experimentation environments.
- Privacy-preserving collaboration across functions.
- Rapid prototyping with realistic simulations.
- Forward-looking scenario modeling.
Over time, this capability can transform how organizations think about risk, experimentation, and strategic planning. Instead of treating innovation as a series of isolated initiatives, they can design systems that continuously generate insights and opportunities.
A Shift in Mindset
The move from data scarcity to data abundance requires more than technology adoption. It requires a mindset shift. Leaders must begin to see data not only as something to protect and analyze, but also as something that can be intentionally generated to enable exploration.
In this future-oriented model, synthetic data becomes a bridge between imagination and implementation. It allows teams to explore bold ideas safely, refine them through simulation, and bring them into the real world with greater confidence.
When organizations embrace this perspective, they expand their capacity to learn, adapt, and innovate in environments defined by uncertainty. Synthetic data does not replace reality — it helps organizations prepare for it.
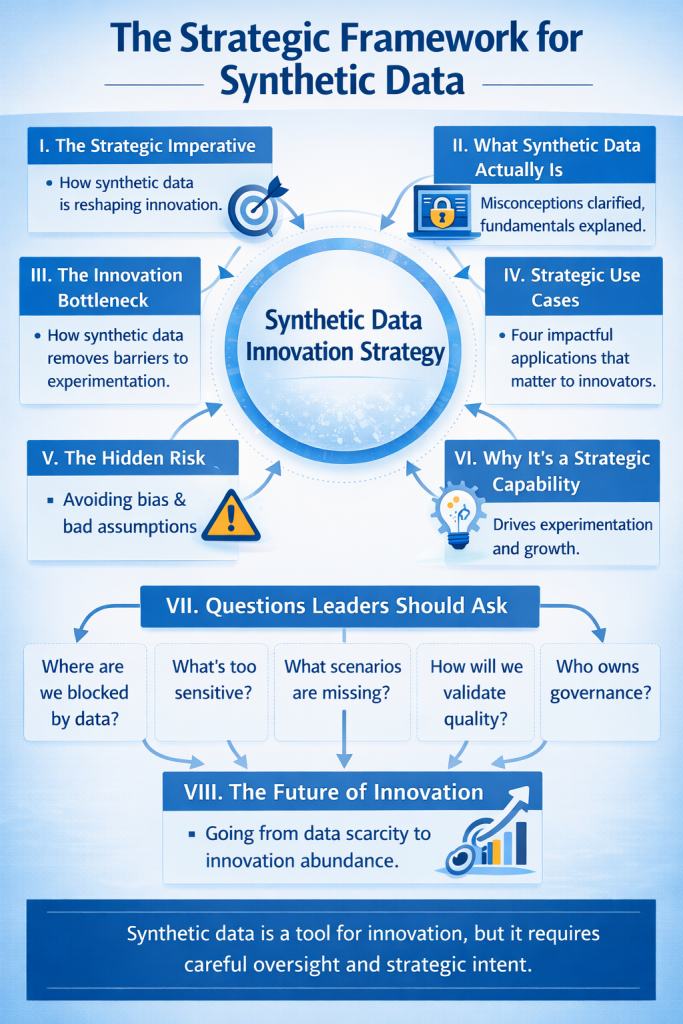
Closing Thought
Innovation has always depended on imagination. What is changing in the modern era is the ability to test that imagination safely, quickly, and at scale. Synthetic data generation represents more than a technical advancement — it represents an expansion of what organizations can responsibly explore.
When used thoughtfully, synthetic data helps teams move beyond the limits of historical datasets. It enables experimentation without exposing sensitive information, supports collaboration across silos, and creates environments where new ideas can be evaluated before they reach customers or production systems.
But the real opportunity is not simply to generate more data. The opportunity is to generate better conditions for learning. Innovation thrives where curiosity is encouraged, where experimentation is safe, and where insights can be tested without unnecessary friction.
Synthetic data becomes powerful when it is aligned with human-centered principles — when it strengthens privacy, improves access to experimentation, and supports responsible decision-making. It should not replace real-world understanding, but rather complement it, expanding the space in which discovery can occur.
In the end, organizations that treat synthetic data as part of their innovation infrastructure are not just adopting a new tool. They are building a capability that allows them to learn faster, adapt more confidently, and pursue bolder ideas with greater responsibility.
The future of innovation will belong to organizations that can balance rigor with imagination — and synthetic data, applied wisely, can help make that balance possible.
Frequently Asked Questions About Synthetic Data
What is synthetic data and why does it matter for innovation?
Synthetic data is artificially generated data that mimics the statistical patterns and structure of real-world datasets without exposing actual individuals or sensitive records. It allows organizations to experiment, train AI systems, and test new ideas even when real data is limited, restricted, or too sensitive to use. For innovation leaders, synthetic data creates a safe environment to explore possibilities, simulate future scenarios, and accelerate experimentation without compromising privacy or compliance.
How is synthetic data different from anonymized data?
Anonymized data begins as real data and then removes or masks identifying information. While this reduces risk, it can still leave traces that may be re-identified in some circumstances. Synthetic data, on the other hand, is generated by models that reproduce patterns found in real datasets without copying actual records. The result is a dataset that behaves like real data but does not contain real people or events, making it far safer for experimentation, collaboration, and AI training.
What should leaders consider before investing in synthetic data?
Leaders should view synthetic data as a strategic capability rather than just a technical tool. Key considerations include identifying innovation initiatives currently blocked by limited or sensitive data, ensuring proper validation of synthetic datasets, establishing governance over how synthetic data is generated and used, and confirming that the models creating the data do not unintentionally amplify bias. When implemented responsibly, synthetic data can significantly expand an organization’s ability to experiment and innovate.
Disclaimer: This article speculates on the potential future applications of cutting-edge scientific research. While based on current scientific understanding, the practical realization of these concepts may vary in timeline and feasibility and are subject to ongoing research and development.
Image credits: ChatGPT
 Sign up here to get Human-Centered Change & Innovation Weekly delivered to your inbox every week.
Sign up here to get Human-Centered Change & Innovation Weekly delivered to your inbox every week.